

通义千问开源视觉语言模型qwen2
2024-10-09 【 字体:大 中 小 】

8月30日,阿里通义千问开源第二代视觉语言模型Qwen2-VL,推出2B、7B两个尺寸及其量化版本模型。Qwen2-VL在多个权威测评中创造了同等规模开源模型的最佳成绩,能够识别不同分辨率和长宽比的图片,能够理解20分钟以上长视频,还具备自主操作手机和机器人的视觉智能体能力。
2023年8月,通义千问开源第一代视觉语言理解模型Qwen-VL,成为开源社区最受欢迎的多模态模型之一。短短一年内,模型下载量突破1000万次。目前,多模态模型在手机、车端等各类视觉识别场景的落地正在加速,开发者和应用企业也格外关注Qwen-VL的升级迭代。


千呼万唤,Qwen2-VL交出了成绩单。相比上代模型,Qwen2-VL的基础性能全面提升。可以读懂不同分辨率和不同长宽比的图片,在DocVQA、RealWorldQA、MTVQA 等基准测试创下全球领先的表现;可以理解20分钟以上长视频,支持基于视频的问答、对话和内容创作等应用;具备强大的视觉智能体能力,可自主操作手机和机器人,借助复杂推理和决策的能力,Qwen2-VL 可以集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作;能理解图像视频中的多语言文本,包括中文、英文,大多数欧洲语言,日语、韩语、阿拉伯语、越南语等。
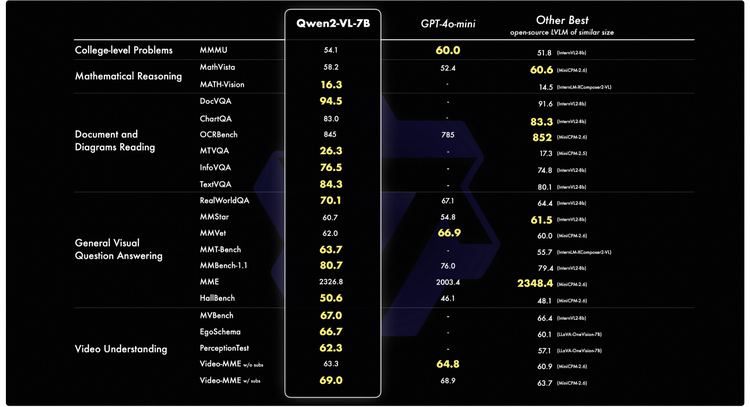
通义千问团队从六个方面评估了模型能力,包括综合的大学题目、数学能力、文档表格多语言文字图像的理解、通用场景问答、视频理解、Agent 能力。Qwen2-VL-7B以其“经济型”参数规模实现了极具竞争力的性能表现;Qwen2-VL-2B则可支持移动端的丰富应用,同样具备完整图像视频多语言的理解能力,在视频文档和通用场景问答方面,相比同规模模型优势显著。
Qwen2-VL延续了 ViT 加 Qwen2 的串联结构,三个尺寸的模型都采用了 600M 规模大小的 ViT,支持图像和视频统一输入。研发团队还在架构上作了两大改进,一是实现了对原生动态分辨率的全面支持,不同于上代模型,Qwen2-VL 能够处理任意分辨率的图像输入,这一设计模拟了人类视觉感知的自然方式,赋予模型处理任意尺寸图像的强大能力;二是使用了多模态旋转位置嵌入(M-ROPE)方法,传统的旋转位置嵌入只能捕捉一维序列的位置信息,M-ROPE 使得大规模语言模型能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息,赋予了语言模型强大的多模态处理和推理能力,能让模型更好地理解和建模复杂的多模态数据。

Qwen2-VL模型结构
目前,通义千问团队以Apache 2.0 协议开源了 Qwen2-VL-2B 和 Qwen2-VL-7B,开源代码已集成到 Hugging Face Transformers、vLLM 和其他第三方框架中。开发者可以通过Hugging Face 和魔搭ModelScope下载使用模型,也可通过通义官网、通义APP的主对话页面使用模型。

猜你喜欢

中新互免签证除夕落地 “新马泰”说走就走
 5373
5373 按天配资杠杆:高风险高收益的双刃剑
9147 美国又要开辟海底“暗战”?
8332 问财全能式选股股票池20240229
4809 奢侈品卖不动了?LVMH集团上半年净利润下跌14%
8610 限时登陆!这家“老字号”宾馆在白云机场“卖年味”
2155 合并报表:子公司、孙公司,多层级合并,能不能在最终控制层面直接抵消?
962 揭秘热门股票杠杆配资平台,助你投资更轻松
1014 百年金庸的故乡情结
9575 黄金期货配资软件:掘金之路上的智能伙伴
4499 








劳动者之歌|刘伟的焊接“智”造梦

日本央行本周重磅决议!利率不变料板上钉钉,但这一警告必须警惕
北交所迎来第258家公司!今年七成新股,上市首日涨幅翻倍!

变革理念 发挥好险资压舱石作用

赵边骑、齐技击、魏武卒、秦锐士,谁才是称霸战国的精锐军队?_特种部队_士兵_吴起

百世集团第一季度营收65亿元 净亏损同比收窄
中国网络安全产业联盟最新网络安全报告:美国情况报机构无差别对全球手机用户实施攻击

收评:沪指跌066%失守3100点 金融板块逆势拉升

六连阳!澳元美元攀高突破重重关口

威胜信息获得实用新型专利授权:“一种基于罗氏线圈电流采样的导轨式监测装置”

